What is OpenCL and what it is used for?
Apple initiated the development of OpenCL after identifying the need for a standardized way to program different vendors hardware. They needed a way to code once and run on all vendors hardware without the need of targeting all the possible different vendors. Apple developed a framework that could utilize the parallel processing power of GPUs and other specialized processors in consumer devices. They collaborated with industry partners, including AMD, Intel, and NVIDIA, to create the first specification. Apple announced OpenCL as part of macOS 10.6 Snow Leopard in 2008, demonstrating its capability to improve performance in graphics-intensive and scientific applications.
After defining the core OpenCL specification, Apple transferred the management and further development of the standard to the Khronos Group. Apple recognized that for OpenCL to become a true industry standard, it needed to be managed by a neutral, industry-wide consortium. The Khronos Group, known for managing other open standards like OpenGL (for graphics) and Vulkan (for low-level graphics and compute), was ideal for maintaining and promoting OpenCL as it could drive adoption beyond Apple's ecosystem.
The Khronos Group then formed the OpenCL Working Group, where industry stakeholders, including Apple, AMD, Intel, NVIDIA, ARM, and others, could contribute to OpenCL’s evolution. This transfer allowed OpenCL to gain wider acceptance and support across multiple hardware and software platforms, ensuring that OpenCL could serve as a truly cross-platform, vendor-neutral standard for parallel computing.
Picture of OpenCL logo written in ASCII.
The Importance of A Standard Framework
A standardized framework for parallel computing, like OpenCL, is essential because it enables software to run efficiently across diverse hardware types and platforms, allowing developers to write code once and deploy it universally. This compatibility optimizes resource use by letting applications leverage the best-suited processors (CPUs, GPUs, etc.) for specific tasks, leading to improved performance and efficiency. Standardization also reduces development time and costs, fosters innovation by avoiding vendor lock-in, and ensures code longevity by providing a stable, widely supported foundation. As a result, it powers advancements in fields like AI, scientific computing, and data analytics by making high-performance computing accessible and adaptable across different devices.
Having a standardized framework for parallel computing, like OpenCL, is important for these reasons, between others:
- Cross-Platform Compatibility
- Optimized Resource Utilization
- Encourages Innovation and Competition
- Reduces Development Costs and Time
- Enables Scientific and Data-Intensive Applications
- Future-Proofing Code
- Community and Ecosystem Development
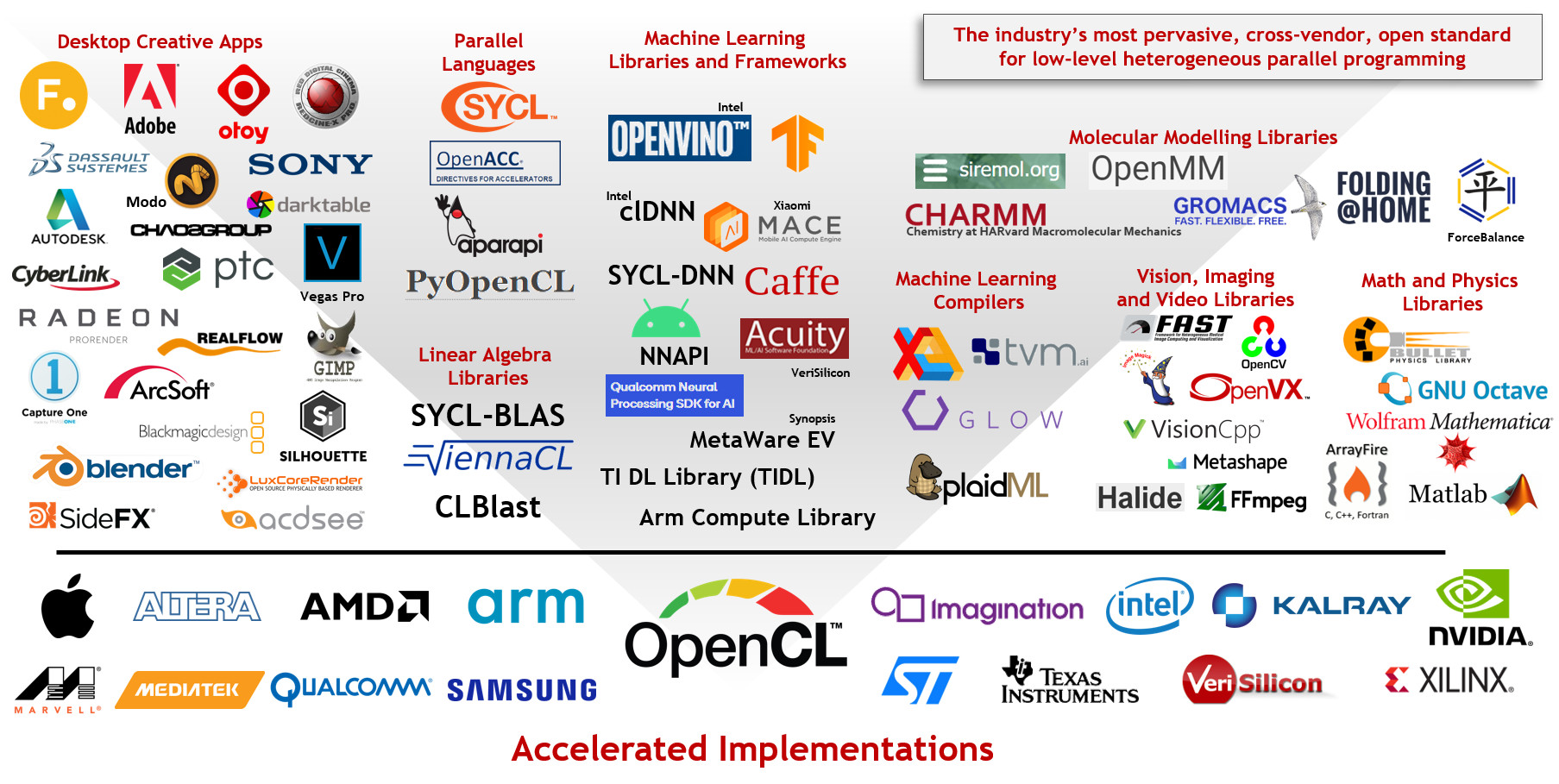
OpenCL is widely deployed and used throughout the industry - source here
OpenCL Application Live-cicle
An OpenCL application typically starts by setting up the platform and device context, which involves choosing a platform (such as AMD, Intel, or NVIDIA) and the specific devices (CPUs, GPUs, or other accelerators) that the application will use for computation. The developer queries the available devices on the chosen platform and creates an OpenCL context, which serves as a container to manage these devices and facilitate data and command sharing among them. Once the context is established, a command queue is created for each device, which will handle the tasks or "kernels" (units of code for parallel execution) sent to the device.
The next step is memory management and data transfer. OpenCL uses a unique memory model that requires the developer to specify the data that needs to be processed and allocate buffers (memory objects) within the context. These buffers are created in the device’s memory and linked to host data on the main CPU, which enables transferring data between the host and the device. After setting up the necessary memory objects, data is then transferred (or "mapped") from the host to the device’s memory so that it can be accessed by the kernels during execution.
The final stage involves kernel execution and result retrieval. The developer writes OpenCL kernels, which are functions designed to execute on the device in parallel. After compiling these kernels, they are enqueued into the command queue for execution. The application waits for the kernels to complete their tasks, then retrieves the results by transferring the data back from the device’s memory to the host. To ensure efficient operation, OpenCL applications can also use event synchronization to manage dependencies and optimize command execution. Once the computations are done, all resources, including buffers, command queues, and contexts, are released to free up memory.
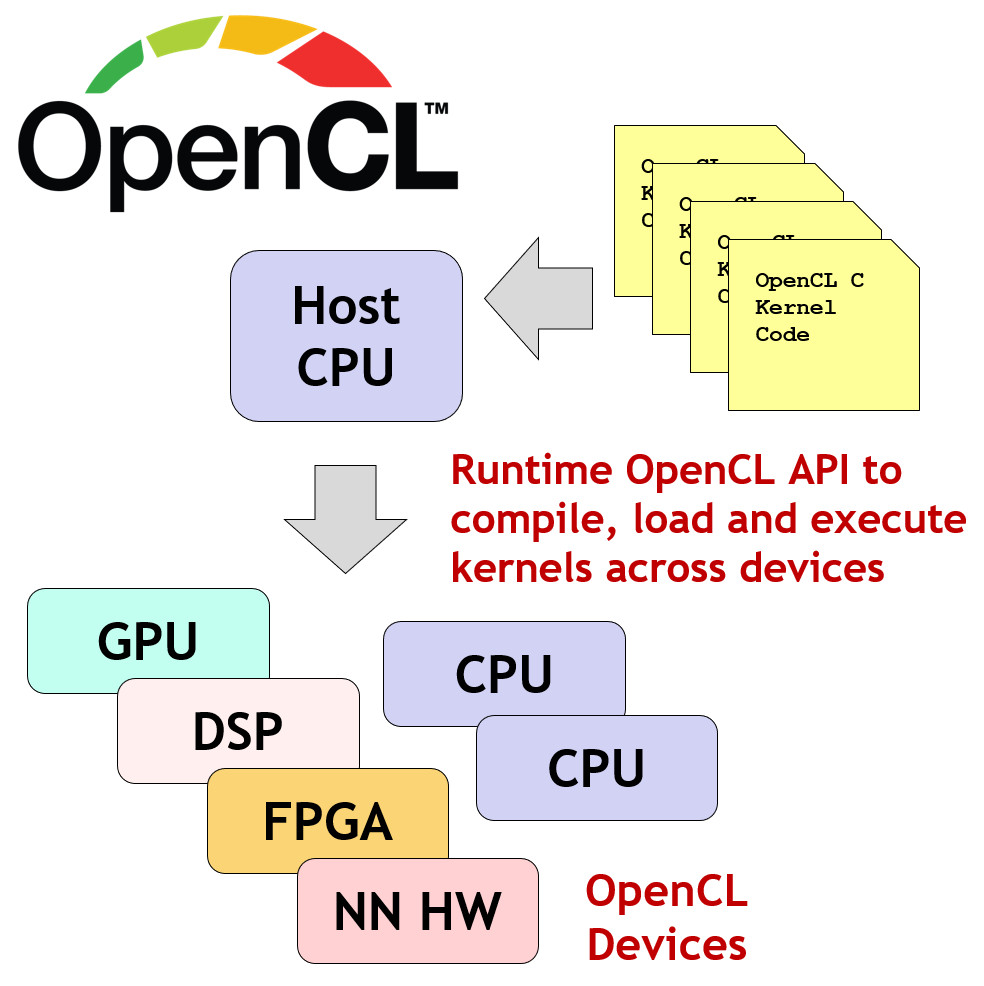
Compiling and Executing OpenCL Kernels - source here
OpenCL Versions
OpenCL started with version 1.0, released in 2008, establishing its foundation as a cross-platform framework for parallel computing. This initial version introduced core elements like kernels, memory objects, and command queues, allowing developers to harness the processing power of various devices (CPUs, GPUs, and accelerators) within a single application. It also introduced the basic syntax and functions of the OpenCL C programming language, which defined how kernels (functions for parallel execution) are written and managed. Version 1.1 brought enhancements like improved memory management with new buffer and image types, as well as new data-transfer functions that made it easier to manage complex data types across devices.
OpenCL version 1.2, launched in 2011, further matured the framework by adding custom device support and features like partitioning a device into sub-devices, which allowed finer-grained control over hardware resources. It also introduced support for separate compilation and linking of kernels, making code management more modular and flexible. Version 2.0, released in 2013, marked a significant evolution, with major additions like Shared Virtual Memory (SVM) that allowed the host and device to share memory, making it easier to manage data. Version 2.0 also added support for device-side enqueue, enabling devices to launch kernels directly, and provided enhanced atomic functions for finer synchronization control, which was particularly useful for more complex computations and nested parallelism.
The latest version, OpenCL 3.0, was released in 2020 and emphasized backward compatibility and flexibility. OpenCL 3.0 introduced a modular approach, allowing vendors to implement only the features they needed, while still adhering to the standard. This version also retained key features from OpenCL 1.2 as a baseline, making it more accessible for diverse devices and simpler hardware. Additionally, it included updates to improve support for SPIR-V (an intermediate representation for easier portability across OpenCL and Vulkan), making it simpler to integrate OpenCL with other frameworks. By focusing on flexibility and backwards compatibility, OpenCL 3.0 modernized the standard, allowing it to adapt to a wide range of applications and device capabilities.
All the Registry about the versions can be found here.
How to Get Started Using OpenCL
The Khronos Group maintains the official OpenCL specification and guides on their website, which are essential for understanding the core concepts.
The Khronos group mainatains a guide on github, KhronosGroup - OpenCL-Guide.
Additionally, to all those resources the specification documentation is a perfect place to search for reference.
For all those that love reading books, I recommend the following books:

This book by Matthew Scarpino, provides a project-based approach to learning OpenCL, with real-world examples and practical exercises. It’s a great resource if you prefer hands-on learning, as it focuses on applying OpenCL to real computational problems, from image processing to scientific computing.

This book goes deeper into using OpenCL across various platforms, including both CPUs and GPUs. It’s an excellent resource for understanding the practical side of OpenCL and working on heterogeneous systems, making it suitable for readers who want to leverage OpenCL in diverse computing environments.

This book is often recommended for its thorough explanation of OpenCL basics, code samples, and exercises to build a strong foundation. It introduces concepts progressively and offers guidance on writing efficient OpenCL code for different hardware.
These resources offer a solid foundation in OpenCL, and using them in combination with the official Khronos Group documentation is a great way to start building OpenCL applications effectively.
If you spot any typos, have questions, or need assistance with the build, feel free to contact me at: antonimercer@lthjournal.com
This guide contains no affiliate links or ads. If you'd like to support this or future projects, you can do so here:
By supporting monthly you will help me create awesome guides and improve current ones.

Technologies used
Debian 12, Linux, OpenCL, C++, AMD, Nvidia, Intel, GPU